The Document Parser automatically extracts key information, like Aadhaar, PAN, and Passport numbers, from legal documents. It streamlines the process of handling large volumes of data by automating the extraction of relevant details.
Using machine learning, the Document Parser analyzes the structure of documents to identify key data points such as names, dates, addresses, and other relevant information. Once identified, the data is extracted and made available within the application.
For more details on how the Document Parser works and its benefits for end-users, watch the video below.
¶ Document Parser - Properties
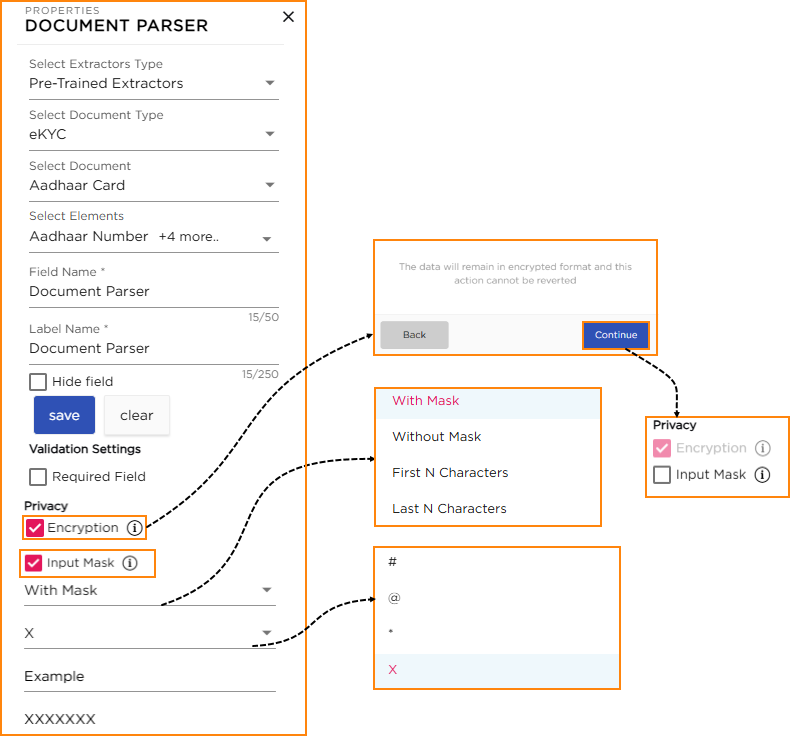
- Select Extractors Type: Choose the type of extractors used to automatically extract key information from documents like Aadhaar, Passport, or PAN.
- Select Document Type: The Document type is eKYC by default.
- Select Document: Select the document from predefined options, including Aadhar Card, Passport (IND), and Permanent Account Number (PAN).
- Select Elements: Choose the specific elements of the selected document that need to be extracted. These elements will be configured upon selecting the document.
- Field Name: Provide a unique name for the field which is visible for CDs while building application.
- Label Name: Provide a unique name for the field which will be visible for the end-users.
- Hide Field: Hides the field from being viewed.
¶ Validation Settings
Required Field: This ensures that the users provide necessary information in the field, preventing any important data from being overlooked or omitted.
¶ Privacy
- Encryption: Turn this on to keep the field’s data encrypted and secure.
- Once enabled, you can’t turn it off later.
- The data will always stay encrypted.
- How it appears to users (masked or visible) depends on admin settings set at the organization level.
- Input Mask: Define how the data appears when users enter it into the field. The available options are:
- With Mask: Hide all characters using a selected symbol (e.g., X, #, @, *).
- Without Mask: Show the data exactly as entered, without any masking.
- Show First N Characters: Display the first few characters and mask the remaining.
- Show Last N Characters: Mask the beginning and display only the last few characters.
¶ Field Themes
¶ Font Properties
- Field Label Color: Choose or modify the color of the label name.
- Field Label Size: Select the label size: Small, Medium, Large, or Custom.
- Field Label Style: Apply styles such as Bold or Italic to the label name